
As explained at the introduction to Castor JDO, Castor has support for many advanced features such as caching. The below sections detail the features related to caching in Castor JDO, as their understanding is required to use Castor JDO in a performant and secure way.
In general, performance caches enhance the application performance by reducing the number of read operations against the persistence storage, by storing and reusing the last read or committed values of the object. Performance caches do not affect the behavior of short transactions or locking. It only affects persistence objects that have been released from any transactional context.
Starting from Castor 0.8.6, a performance cache implementation has been added. At a technical level, Castor maintains separate (performance) caches for each object type specified in the JDO mapping provided, allowing users to specify - for each object type individually - the type and capacity of the cache.
By default, the following cache types are available:
Table 4.1. Available cache types
| name | Vendor | Version | Distributable? | Open source/commercial | high volume/performance | Added in release |
|---|---|---|---|---|---|---|
| none | Built-in | - | No | Open Source | No | |
| unlimited | Built-in | - | No | Open Source | No | |
| count-limited | Built-in | - | No | Open Source | No | |
| time-limited | Built-in | - | No | Open Source | No | |
| coherence | Tangosol Coherence | 2.5 | Yes | Commercial | Yes | 0.9.9 |
| jcs | JCS | 1.2.5 | Yes | Open source | Yes | 0.9.9 |
| fkcache | FKCache | 1.0-beta6 | No | Open Source | No | 0.9.9 |
| oscache | OSCache | 2.5 | Yes | Open Source | No | 1.0 |
| fifo | Built-in | - | No | Open Source | Yes | 1.0 |
| lru | Built-in | - | No | Open Source | Yes | 1.0 |
| ehcache | Built-in | - | Yes | Open Source | ? | 1.0.1 |
| gigaspaces | JCS | 5.0 | Yes | Commercial | Yes | 1.0.1 |
As some of these cache providers allow for allow you to use it in a distributed mode, this allows Castor JDO to be used in a clustered (multi-JVM) environment. Please see the section below for short summary of this feature.
Per definition, all build-in performance caches are write-through, because all changes to objects as part of a transaction should be persisted into the cache at commit time without delay.
For problems related to the use of performance caches, please consult with the relevant entries in the JDO F.A.Q..
As it stands currently, performance caches also serve a dual purpose as dirty checking caches for long-transactions. This limitation implies that the object's availability in the performance cache determines the allowed time span of a long transaction.
This might become an issue when performance caches of type 'count-limited' or 'time-limited' are being used, where objects will eventually be disposed. If an application tries to update an object that has been disposed from the dirty checking cache, an ObjectModifedException will be thrown.
The DTD declaration is as follows:
<!ELEMENT cache-type ( param* )> <!ATTLIST cache-type type ( none | count-limited | time-limited | unlimited | coherence | fkcache | jcache | jcs | oscache | fifo | lru | ehcache | gigaspaces ) "count-limited" debug (true|false) "false" capacity NMTOKEN #IMPLIED> <!ELEMENT param EMPTY> <!ATTLIST param name NMTOKEN #REQUIRED value NMTOKEN #REQUIRED>
With release 1.0 of Castor the DTD has changed but it is backward compatible to the old one and allows to enable debugging of cache access for a specific class as well as passing individual configuration parameters to each cache instance. Only count-limited and time-limited of the current build-in cache types support parameters. Parameter names are case sensitive and are silently ignored if they are unknown to a cache type.
It need to be noted that there are 3 parameter names that are reserved for internal use. If you specify a parameter with one of the names: type, name or debug their value will silently be overwritten with another one used internally.
Example 4.1. Configuration sample - count-limited
A count-limited least-recently-used cache (LRU) for 500 objects can be specified by:
<cache-type type="count-limited" capacity="500"/>
or
<cache-type type="count-limited"/> <param name="capacity" value="500"/> </cache-type>
If both, the capacity attribute and parameter with name="capacity" is specified, the parameter value takes precedence over the attribute value.
Example 4.2. Configuration sample - time-limited
A time-limited first-in-first-out cache (FIFO) that expires objects after 15 minutes can be specified by:
<cache-type type="time-limited" capacity="900"/>
or
<cache-type type="time-limited"/> <param name="ttl" value="900"/> </cache-type>
If both, the capacity attribute and parameter with name="ttl" is specified, the parameter value takes precedence over the attribute value.
The debug attribute can be used to enable debugging for objects of a single class. In addition to setting this attribut to true you also need to set logging level of org.castor.cache.Cache to debug.
![[Note]](images/admons/note.png) | Note |
|---|---|
The default cache-type is |
The cache types fifo and lru are based on a set of articles in the O'Reilly Network by William Grosso, to implement a simplified and 1.3-compatible implementation of a Hashbelt algorithm.
Hashbelts are simple, in principle. Instead of walking all objects and finding out when they're supposed to expire, use a "conveyor belt" approach. At any particular point in time, objects going into the cache go into the front of the conveyor belt. After a certain amount of time or when the size limit of a container has been reached, move the conveyor belt - put a new, empty container at the front of the conveyor belt to catch new objects, and the one that drops off of the end of the conveyor belt is, by definition, ready for garbage collection.
As seen in his system, you can use a set of pluggable strategies to implement the actual hashbelt bits. A container strategy allows you to change out the implementation of the container itself - from simple hashtable-based implementations, up through more complex uses of soft referenced or hashset-based implementations, depending on what you need and what you want it to be used for. A pluggable "expire behavior" handler allows you to determine what action is taken on something which drops off of the bottom of the conveyor belt.
In difference to all other cache types the fifo and lru cache types offer various configuration options. Both of them have 6 parameters to configure their behaviour.
Table 4.2. cache types parameters
| parameter | description |
|---|---|
| containers | The number of containers in the conveyor belt. For example: If a box will drop off of the conveyor belt every 30 seconds, and you want a cache that lasts for 5 minutes, you want 5 / 30 = 6 containers on the belt. Every 30 seconds, another, clean container goes on the front of the conveyor belt, and everything in the last belt gets discarded. If not specified 10 containers are used by default. For systems with fine granularity, you are free to use a large number of containers; but the system is most efficient when the user decides on a "sweet spot" determining both the number of containers to be managed on the whole and the optimal number of buckets in those containers for managing. This is ultimately a performance/accuracy tradeoff with the actual discard-from-cache time being further from the mark as the rotation time goes up. Also the number of objects discarded at once when capacity limit is reached depends upon the number of containers. |
| capacity | Maximum capacity of the whole cache. If there are, for example, ten containers on the belt and the capacity has been set to 1000, each container will hold a maximum of 1000/10 objects. Therefore if the capacity limit is reached and the last container gets droped from the belt there are up to 100 objects discarted at once. By default the capacity is set to 0 which causes capacity limit to be ignored so the cache can hold an undefined number of objects. |
| ttl | The maximum time an object lifes in cache. If the are, for example, ten containers and ttl is set to 300 seconds (5 minutes), a new container will be put in front of the belt every 300/10 = 30 seconds while another is dropped at the end at the same time. Due to the granularity of 30 seconds, everything just until 5 minutes 30 seconds will also end up in this box. The default value for ttl is 60 seconds. If ttl is set to 0 which means that objects life in cache for unlimited time and may only discarded by a capacity limit. |
| monitor | The monitor intervall in minutes when hashbelt cache rports the current number of containers used and objects cached. If set to 0 (default) monitoring is disabled. |
| container-class |
The implementation of
org.castor.cache.hashbelt.container.Container
interface to be used for all containers of the cache.
Castor provides the following 3 implementations of the Container
interface.
|
| reaper-class |
Specific reapers yield different behaviors. The GC reaper,
the default, just dumps the contents to the garbage collector.
However, custom implementations may want to actually do something
when a bucket drops off the end; see the javadocs on other available
reapers to find a reaper strategy that meets your behavior
requirements. Apart of the default
org.castor.cache.hashbelt.reaper.NullReaper we provide
3 abstract implementations of
org.castor.cache.hashbelt.reaper.Reaper interface:
|
Example 4.3. Configuration sample - fifo
A fifo cache with default values explained above is specified by:
<mapping> ... <class name="com.xyz.MyOtherObject"> ... <cache-type type="fifo"/> ... </class> ... </mapping>
Example 4.4. Configuration sample - lru
A lru cache with capacity=300 and ttl=300 is defined by:
<mapping> ... <class name="com.xyz.MyOtherObject"> ... <cache-type type="lru" capacity="300"/> ... </class> ... </mapping>
or better by:
<mapping> ... <class name="com.xyz.MyOtherObject"> ... <cache-type type="lru"> <param name="capacity" value="300"/> <param name="ttl" value="300"/> </cache-type> ... </class> ... </mapping>
Example 4.5. Configuration sample - fifo (custommized)
An example of a customized configuration of a fifo cache is:
<mapping> ... <class name="com.xyz.MyOtherObject"> ... <cache-type type="fifo"/> <param name="container" value="10"/> <param name="capacity" value="1000"/> <param name="ttl" value="600"/> <param name="monitor" value="5"/> <param name="container-class" value="org.castor.cache.hashbelt.container.WeakReferenceContainer"/> <param name="reaper-class" value="org.castor.cache.hashbelt.reaper.NullReaper"/> </cache-type> ... </class> ... </mapping>
All of the cache providers added with release 0.9.9 are distributed caches per se or can be configured to operate in such a mode. This effectively allows Castor JDO to be used in a clustered J2EE (multi-JVM) environment, where Castor JDO runs on each of the cluster instances, and where cache state is automatically snychronized between these instances.
In such an environment, Castor JDO wil make use of the underlying cache provider to replicate/distribute the content of a specific cache between the various JDOManager instances. Through the distribution mechanism of the cache provider, a client of a Castor JDO instance on one JVM will see any updates made to domain objects performed against any other JVM/JDO instance.
Example 4.6. Configuration sample - Coherence
The following class mapping, for example, ...
<mapping> ... <class name="com.xyz.MyOtherObject"> ... <cache-type type="coherence" /> ... </class> ... </mapping>
defines that for all objects of type
com.xyz.MyOtherObject Tangosol's
Coherence cache provider should
be used.
Example 4.7. Configuration sample - Gigaspaces
The following class mapping, for example, ...
<mapping> ... <class name="com.xyz.MyOtherObject"> ... <cache-type type="gigaspaces" /> ... </class> ... </mapping>
defines that for all objects of type
com.xyz.MyOtherObject the
Gigaspaces cache provider should
be used. As Gigspaces supports various cache and clsuer modes, this
cache provider allows product-specific configuration as shown below:
<mapping> ... <class name="com.xyz.MyOtherObject"> ... <cache-type type="gigaspaces" > <param name="spaceURL" value="/./" /> <param name="spaceProperties" value="useLocalCache" /> </cache-type> ... </class> ... </mapping>
As of release 0.9.6, Castor allows for the addition of user-defined cache implementations. Whilst Castor provides a set of pre-built cache providers, offering a variety of different cache algorithms, special needs still might require the application developer to implement a custom cache algorithm. Castor facilitates such need by making available standardized interfaces and an easy to understand recipe for integrating a custom cache provider with Castor.
As explained in org.exolab.castor.jdo.persist
(API docs for the persists package),
org.exolab.castor.persist.LockEngine implements
a persistence engine that caches objects in memory for performance reasons
and thus reduces the number of operations against the persistence storage.
The main component of this package is the interface org.castor.cache.Cache, which declares the external functionality of a (performance) cache. Existing (and future) cache implementations (have to) implement this interface, which is closely modelled after the java.util.Map interface.
Below is a summary of the steps required to build a custom cache provider and register it with Castor JDO:
Create a class that implements org.exolab.castor.persist.cache.Cache.
Create a class that implements org.exolab.castor.persist.cache.CacheFacto
Register your custom cache implementation with Castor JDO in the
castor.properties file.
Please create a class that implements the interface org.exolab.castor.persist.cache.Cache">Cache.
To assist users in this task, a
org.castor.cache.AbstractBaseCache
class has been supplied, which users should derive their custom
org.castor.cache.Cache instances
from, if they wish so. Please consult existing
org.castor.cache.Cache implementations such as
org.castor.cache.simple.TimeLimited} or
org.castor.cache.simple.CountLimited
for code samples.
/** * My own cache implementation */ public class CustomCache extends AbstractBaseCache { ... }
Please add a class that imnplements the
org.castor.cache.CacheFactory interface
and make sure that you provide valid values for the two
properties name and className.
To assist users in this task, a
org.castor.cache.AbstractCacheFactory
class has been supplied, which users should derive their custom
org.castor.cache.CacheFactory instances
from, if they wish so. Please consult existing
org.castor.cache.CacheFactory implementations
such as org.castor.cache.simple.TimeLimitedFactory} or
org.castor.cache.simple.CountLimitedFactory
for code samples.
/** * My own cache factory implementation */ public class CustomCacheFactory extends AbstractCacheFactory { /** * The name of the factory */ private static final String NAME = "custom"; /** * Full class name of the underlying cache implementation. */ private static final String CLASS_NAME = "my.company.project.CustomCache"; /** * Returns the short alias for this factory instance. * @return The short alias name. */ public String getName() { return NAME; } /** * Returns the full class name of the underlying cache implementation. * @return The full cache class name. */ public String getCacheClassName() { return CLASS_NAME; } }
The file castor.properties holds a property
org.castor.cache.Factories that enlists the available
cache types through their related CacheFactory instances.
# # Cache implementations # org.castor.cache.Factories=\ org.castor.cache.simple.NoCacheFactory,\ org.castor.cache.simple.TimeLimitedFactory,\ org.castor.cache.simple.CountLimitedFactory,\ org.castor.cache.simple.UnlimitedFactory,\ org.castor.cache.distributed.FKCacheFactory,\ org.castor.cache.distributed.JcsCacheFactory,\ org.castor.cache.distributed.JCacheFactory,\ org.castor.cache.distributed.CoherenceCacheFactory,\ org.castor.cache.distributed.OsCacheFactory,\ org.castor.cache.hashbelt.FIFOHashbeltFactory,\ org.castor.cache.hashbelt.LRUHashbeltFactory
To add your custom cache implementation, please append the fully-qualified class name to this list as shown below:
#
# Cache implementations
#
org.castor.cache.Factories=\
org.castor.cache.simple.NoCacheFactory,\
org.castor.cache.simple.TimeLimitedFactory,\
org.castor.cache.simple.CountLimitedFactory,\
org.castor.cache.simple.UnlimitedFactory,\
org.castor.cache.distributed.FKCacheFactory,\
org.castor.cache.distributed.JcsCacheFactory,\
org.castor.cache.distributed.JCacheFactory,\
org.castor.cache.distributed.CoherenceCacheFactory,\
org.castor.cache.distributed.OsCacheFactory,\
org.castor.cache.hashbelt.FIFOHashbeltFactory,\
org.castor.cache.hashbelt.LRUHashbeltFactory,\
org.whatever.somewhere.nevermind.CustomCacheSometimes it is necessary to interact with Castor's (performance) caches to e.g. (selectively) clear a Castor cache of its content, or inquire about whether a particular object instance (as identified by its identity) is cached already.
For this purpose a
org.exolab.castor.jdo.CacheManager can
be obtained from a org.exolab.castor.jdo.Database
instance by issuing the following code:
JDO jdo = ....; Database db = jdo.getDatabase(); CacheManager manager = db.getCacheManager();
This instance can subsequently be used to selectively clear the Castor performance cache using one of the following methods:
org.exolab.castor.jdo.CacheManager.expireCache()
org.exolab.castor.jdo.CacheManager.expireCache(Class,Object)
org.exolab.castor.jdo.CacheManager.expireCache(Class,Object[])
org.exolab.castor.jdo.CacheManager.expireCache(Class[])
To inquire whether an object has already been cached, please use the following method:
org.exolab.castor.jdo.CacheManager.isCached (Class, Object);
Please note that once you have closed the Database instance from which you
have obtained the CacheManager, the CacheManager cannot be used anymore and
will throw a
org.exolab.castor.jdo.PersistenceException.
Release 0.9.6:
Added support for LIMIT clause for MS SQL Server.
In the case a RDBMS does not support LIMIT/OFFSET clauses, a SyntaxNotSupportedException is thrown.
Added support for a limit clause and an offset clause. Currently, only HSQL, mySQL and postgreSQL are supported.
Added an example section.
The Castor OQL implementation is currently in phase 3 of development.
| Note |
|---|---|
This documentation is not yet finished |
This document describes an OQL to SQL translator to be added to the Castor JDO Java object Persistence API. The translator will accept OQL queries passed as strings, and generate a parse tree of the OQL. It will then traverse the tree creating the appropriate SQL. The user will then be able to bind parameters to parameterized queries. Type checking will be performed on the bound parameters. When the user executes the query, the system will submit the query to the SQL database, and then postprocess the SQL resultset to create the appropriate result as a Java Object or literal. The current org.exolab.castor.mapping and org.exolab.castor.persist packages will be used for metadata and RDBMS communication.
Four of the (now defunct) SourceXchange milestones for this project call for java source code. These milestones will be referred to here as phase 1, 2, 3, and 4. There are many possible OQL features that can be supported, but weren't discussed in the proposal or RFP. Many of these are probably unwanted. These additional features are specified as phase 5, which is out of the scope of this SourceXChange project.
The parser will construct a parse tree as output from an OQL query string given as input. The OQL syntax is a subset of the syntax described in the ODMG 3.0 specification section 4.12, with some additional constructs. Following is a description of the supported OQL syntax, and its SQL equivalent.
Certain features of OQL may not be directly translatable to SQL, but may still be supported, by post processing the query. For example, the first() and last() collection functions supported in OQL are not directly translatable to standard SQL, but a resultset can be post-processed to return the appropriate values. Features requiring post-processing of SQL resultsets will be documented as such below.
Currently the OQLQuery checks for correct syntax at the same time as it does type checking and other types of error checking. The new code will involve a multiple pass strategy, with the following passes:
Parse the String query checking for syntax errors, and return a parse tree.
Traverse the parse tree checking for correct types, valid member and method identifiers, and use of features which are unsupported. This pass may also generate some data necessary for creating the SQL.
Traverse the tree one final time, creating the equivalent SQL statement to the OQL Query originally passed.
This section describes the first pass which will be done by the parser. The parser will create a StringTokenizer like this:
StringTokenizer tokenizer
= new StringTokenizer(oql,
"\n\r\t,.()[]+-*/<>=:|$", true);This will create a StringTokenizer with the delimiter characters listed in the second argument, and it will return delimeters as well as tokens. The parser will also create a Vector to be used as a token buffer. As tokens are returned from the StringTokenizer they will be added to the Vector. Older tokens will be removed from the Vector when it reaches a certain size. The Vector will also be modified when the StringTokenizer returns multi character operators as seperate tokens, for example the -> method invocation operator.
The parser will consume tokens from the StringTokenizer, generating a ParseTree. Each ParseTree node will have a nodeType corresponding to its symbol in the OQL syntax. After each node is created it will look at the next token and act acordingly, either modifying its properties (i.e. for DISTINCT property of selectExpr), creating a new child node or returning an error. If the error travels up to the root node of the ParseTree, there is a syntax error in the OQL submitted. At the end of this pass, the ParseTree will contain an apropriate representation of the query, which will be analyzed, and used to create SQL. Below is the modified EBNF which will be the Castor OQL syntax.
query ::= selectExpr
| expr
selectExpr ::= select [distinct]
projectionAttributes
fromClause
[whereClause]
[groupClause]
[orderClause]
[limitClause [offsetClause]]
projectionAttributes ::= projectionList
| *
projectionList ::= projection {, projection }
projection ::= field
| expr [as identifier]
fromClause ::= from iteratorDef {, iteratorDef}
iteratorDef ::= identifier [ [as ] identifier ]
| identifier in identifier
whereClause ::= where expr
groupClause ::= group by fieldList {havingClause}
havingClause ::= having expr
orderClause ::= order by sortCriteria
limitClause ::= limit queryParam
offsetClause ::= offset queryParam
sortCriteria ::= sortCriterion {, sortCriterion }
sortCriterion ::= expr [ (asc | desc) ]
expr ::= castExpr
castExpr ::= orExpr
| ( type ) castExpr
orExpr ::= andExpr {or andExpr}
andExpr ::= quantifierExpr {and quantifierExpr}
quantifierExpr ::= equalityExpr
| for all inClause : equalityExpr
| exists inClause : equalityExpr
inClause ::= identifier in expr
equalityExpr ::= relationalExpr
{(= | !=)
[compositePredicate] relationalexpr }
| relationalExpr {like relationalExpr}
relationalExpr ::= additiveExpr
{(< | <=
| > | >= )
[ compositePredicate ] additiveExpr }
| additiveExpr between
additiveExpr and additiveExpr
compositePredicate ::= some | any | all
additiveExpr ::= multiplicativeExpr
{+ multiplicativeExpr}
| multiplicativeExpr
{- multiplicativeExpr}
| multiplicativeExpr
{union multiplicativeExpr}
| multiplicativeExpr
{except multiplicativeExpr}
| multiplicativeExpr
{|| multiplicativeExpr}
multiplicativeExpr ::= inExpr {* inExpr}
| inExpr {/ inExpr}
| inExpr {mod inExpr}
| inExpr {intersect inExpr}
inExpr ::= unaryExpr {in unaryExpr}
unaryExpr ::= + unaryExpr
| - unaryExpr
| abs unaryExpr
| not unaryExpr
| postfixExpr
postfixExpr ::= primaryExpr{[ index ]}
| primaryExpr
{(. | ->)identifier[arglist]}
index ::= expr {, expr}
| expr : expr
argList ::= ([ valueList ])
primaryExpr ::= conversionExpr
| collectionExpr
| aggregateExpr
| undefinedExpr
| collectionConstruction
| identifier[ arglist ]
| queryParam
| literal
| ( query )
conversionExpr ::= listtoset( query )
| element( query )
| distinct( query )
| flatten( query )
collectionExpr ::= first( query )
| last( query )
| unique( query )
| exists( query )
aggregateExpr ::= sum( query )
| min( query )
| max( query )
| avg( query )
| count(( query | * ))
undefinedExpr ::= is_undefined( query )
| is_defined( query )
fieldList ::= field {, field}
field ::= identifier: expr
collectionConstruction ::= array([valueList])
| set([valueList])
| bag([valueList])
| list([valueList])
| list(listRange)
valueList ::= expr {, expr}
listRange ::= expr..expr
queryParam ::= $[(type)]longLiteral
type ::= [unsigned] short
| [unsigned] long
| long long
| float
| double
| char
| string
| boolean
| octet
| enum [identifier.]identifier
| date
| time
| interval
| timestamp
| set <type>
| bag <type>
| list <type>
| array <type>
| dictionary <type, type>
| identifier
identifier ::= letter{letter| digit| _}
literal ::= booleanLiteral
| longLiteral
| doubleLiteral
| charLiteral
| stringLiteral
| dateLiteral
| timeLiteral
| timestampLiteral
| nil
| undefined
booleanLiteral ::= true
| false
longLiteral ::= digit{digit}
doubleLiteral ::= digit{digit}.digit{digit}
[(E | e)[+|-]digit{digit}]
charLiteral ::= 'character'
stringLiteral ::= "{character}"
dateLiteral ::= date
'longliteral-longliteral-longliteral'
timeLiteral ::= time
'longliteral:longLiteral:floatLiteral'
timestampLiteral ::= timestamp
'longLiteral-longLiteral-longLiteral
longliteral:longLiteral:floatLiteral'
floatLiteral ::= digit{digit}.digit{digit}
character ::= letter
| digit
| special-character
letter ::= A|B|...|Z|
a|b|...|z
digit ::= 0|1|...|9
special-character ::= ?|_|*|%|\
The following symbols were removed from the standard OQL Syntax for the following reasons:
andthen: Cannot be implemented in a single SQL query.
orelse: Same as above.
import: This is advanced functionality which may be added later. This phase will use the castor mapping mechanism to define the namespace.
Defined Queries: This is another feature which can be added later. It is unclear where the queries would be stored, and what their scope would be seeing as how this project is an OQL to SQL translator, and not an ODBMS.
iteratorDef was changed so that all instances of expr were replaced by identifier. This means that the from clause can only contain extent names (class names), rather than any expression. This is the most common case and others could create complicated SQL sub-queries or post-processing requirements.
objectConstruction and structConstruction were removed. What is the scope of the constructed object or struct, and how is a struct defined in Java?
The following symbols were added or modified.
between added to relationalExpr.
Optional type specification added to queryParam.
The rest of the standard OQL syntax remains unchanged. Certain syntactically correct queries may not be supported in Castor. For example, top level expressions which do not contain a selectExpr anywhere in the query may not be supported. This will be discussed further in the next section.
The first pass over the ParseTree will do type checking, and create some structures used in the SQL generation pass. It will also check whether the identifiers used are valid, and whether the query uses unsupported features. The following table describes each type of node in the ParseTree, and how it will be processed in the first pass.
Table 4.3. The first pass
| expr |
| Phase 5 |
| projectionAttributes |
| Phase 5 |
| projectionList |
| Phase 5 |
| projection |
| Phase 1 |
| projection |
| Phase 2 |
| fromClause |
| Phase 1 |
| whereClause |
| Phase 1 |
| whereClause |
| Phase 2 |
| whereClause |
| Phase 3 |
| whereClause |
| Phase 4 |
| groupClause, havingClause |
| Phase 4 |
| orderClause |
| Phase 3 |
After the first pass, the ParseTree is free of errors, and ready for the SQL generation step. The existing implementation of the OQLParser uses the persistence API for SQL generation. This API lacks the necessary features to generate SQL from any OQL. The SQLEngine class which implements Persistence is used to create a JDBCQueryExpression. The SQL is derived from the finder, which is a JDBCQueryExpression produced by the SQLEngine. The problem is that the SQLEngine only supports single objects. It cannot generate SQL for path expressions like this:
select p.address from Person p
This query requires a SQL statement like this:
select address.* from person, address
where person.address_id = address.address_idThe buildFinder method should not be used to generate a queryExpression. The SQLEngine should be used to get a ClassDescriptor, and to create a new QueryExpression. The OQLParser should use the methods in the QueryExpression to generate the SQL. The JDBCQueryExpression which is an implementation of QueryExpression is also lacking in necessary features. This class should continue to be used, but the following features will need to be added:
For adding something to select without specifying the tablename, for use with functions (i.e. select count(*))
For when the table has to be added manually.
Add a condition created outside the class, for nested expressions, and other expressions that are not of the form table.column op table.column.
Used for select distinct.
Used for order by
Used for group by
Used for having.
The following table lists each type of tree node, and how it will be processed in the SQL generation pass.
Table 4.4. SQL generation pass
| selectExpr |
| Phase 2 |
| projection |
| Phase 1 |
| projection |
| Phase 2 |
| whereClause |
| Phase 1 |
| whereClause |
| Phase 2 |
| whereClause |
| Phase 4 |
Please see the OQL section of the JDO FAQ.
The Parser and ParseTree classes will be improved through the phases of this project. The top level of OQL to SQL translation will look very simple, like this:
OQLParser parser = new OQLParser(query); ParseTree pt = parser.getParseTree(); pt.checkPass(); //the SQL generation pass _expr = pt.getQueryExpr();
These methods will have some additional parameters passed for storing and retrieving data relevant to the query. Following is a table containing a list of what will be introduced in each coding phase of the project.
Table 4.5. Coding phases
| Phase 1 |
|
| Phase 2 |
|
| Phase 3 |
|
| Phase 4 |
|
| Phase 5: |
|
Please find below various examples of OQL queries using the Java class files as outlined below.
The following fragment shows the Java class declaration for the
Product class:
package myapp; public class Product { private int _id; private String _name; private float _price; private ProductGroup _group; public int getId() { ... } public void setId( int anId ) { ... } public String getName() { ... } public void setName( String aName ) { ... } public float getPrice() { ... } public void setPrice( float aPrice ) { ... } public ProductGroup getProductGroup() { ... } public void setProductGroup( ProductGroup aProductGroup ) { ... } }
The following fragment shows the Java class declaration for the
ProductGroup class:
public class ProductGroup { private int _id; private String _name; public int getId() { ... } public void setId( int id ) { ... } public String getName() { ... } public void setName( String name ) { ... } }
On a selected number of RDBMS, Castor JDO now supports the use of LIMIT/OFFSET clauses.
As per this release, the following RDBMS have full/partial support for this feature.
Table 4.6. Limit support
| RDBMS | LIMIT | OFFSET |
|---|---|---|
| postgreSQL | Yes | Yes |
| mySQL | Yes | Yes |
| Oracle - 1)2) | Yes | Yes |
| HSQL | Yes | Yes |
| MS SQL | Yes | - |
| DB2 | Yes | - |
1) Oracle has full support for LIMIT/OFFSET clauses for release 8.1.6 and later.
2) For the LIMIT/OFFSET clauses to work properly the OQL query is required to include a ORDER BY clause.
The following code fragment shows an OQL query that uses the LIMIT keyword to select the first 10 ProductGroup instances.
query = db.getOQLQuery("select p from ProductGroup as p LIMIT $1");
query.bind(10);
Below is the same OQL query again, restricting the number of ProductGroup instances returned to 10, though this time it is specified that the ProductGroup instances 11 to 20 should be returned.
query = db.getOQLQuery ("select p from ProductGroup as p LIMIT $1 OFFSET $2");
query.bind(10);
In the case a RDBMS does not support LIMIT/OFFSET clauses, a SyntaxNotSupportedException will be thrown.
In order to understand how the JDO transaction model affects applications performance and transactional integrity, you must first understand the semantics of the Java Data Objects. Java Data Objects are objects loaded from and stored to the database, but are disassociated from the database itself. That is, once an object has been loaded into memory, changes to the object in memory are not reflect in the database until the transaction commits.
The following table shows a sample code and the state of the JDO object and the relevant database field:
Table 4.7. JDO objects
| Code | Object value | Record value |
|---|---|---|
results = oql.execute(); | N/A | X |
obj = results.next(); | X | X |
obj.setValue( Y ); | Y | X |
db.commit(); | Y | Y |
Concurrency conflicts do not occur when an object is changed in memory, but rather when the transaction commits and changes are saved back to the database. No changes are saved if the transaction rolls back.
Conflicts could occur if two threads attempted to modify the same object, or the same thread receives two objects associated with the same database record and performs different changes to each object. Castor solves these issues through a transaction-object-identity association.
When the same transaction attempts to query the same database record twice, (e.g. as the result of two different queries) the same object is returned, assuring that different changes will be synchronized through the same object.
When two transactions attempt to query the same database record, each transaction receives a different object mapping to the same record, assuring that changes done in one transaction are not visible to the other transactions. Changes should only become visible when the transaction commits and all its changes are made durable.
This approach places the responsibility of synchronization and deadlock detection on the Castor persistence engine, easing the life of the developer.
Concurrent access requires use of locking to synchronize two transactions attempting to work with the same object. The locking mechanism has to take into account several possible use of objects, as well as help minimize database access through caching and is-modified checking.
Locking modes are declared in the class element of the XML mapping on a per class basis.
The shared mode is the default for all objects, unless otherwise specified in the mapping file. Shared mode allows two transactions to read the same record at the same time. Each transaction will get it's own view of the record as a separate object, to prevent in-memory changes from conflicting with each other. However, the values loaded from the database are the same for both transactions.
When transactions query different objects or query the same objects but for read-only purposes, shared access provides the most efficient means of access in terms of performance, utilizing record caching and eliminating lock contention. For example, when each transaction retrieves a different Customer record and all transactions retrieved the same set of Department records but hardly ever change them, both Customer and Department should be declared as having a shared lock.
However, when two transactions attempt to access the same object, modify it, and commit the changes, a concurrency conflict will occur. Some concurrency conflicts can lead to one of the transactions aborting. For example, if two transactions happen to load the same Account object with a balance of X, one adds 50 and the other adds 60, if both were allowed to commit the changes the new account balance will be either X+50 or X+60, but not X+110.
In the above case either exclusive or db-locked modes should be used to reduce potential conflicts. However exclusive and db-locked modes may cause the application to perform slower due to lock contention and should not be used as the general case. In rare cases conflicts may occur where shared locks are the preferred choice, e.g. when two transactions attempt to modify the same Department object, or somehow get hold of the same Customer records.
Castor detects such conflicts as they occur and uses two mechanisms to deal with them: write locks and deadlock detection. When a transaction commits Castor first tries to determine whether the object has been modified from it's known state (i.e. during query). If the object has not been modified, Castor will not attempt to store the object to the database. If the object has been modified, Castor acquires a write lock on the object preventing other transactions from accessing the object until the current transaction completes storing all changes to the database. A write lock prevents other transactions from acquiring either a write or read lock, preventing them from accidentally loading a dirty image of the object.
If the second transaction has a read lock on the object, the current transaction will block until the second transaction releases the lock, either by rolling back or by not modifying its object. If the other transaction modifies the object and attempts to store it, a deadlock occurs. If both transactions have a read lock, both require a write lock in order to proceed and neither can proceed until the other terminates.
Castor detects such deadlock occurences and causes the second transaction to rollback, allowing the first transaction to commit properly. Such conflicts do not happen often, but when they happen some transactions will fail. The application developer should either be aware of the possibility of failing, or choose to use a more severe lock type.
Conflicts occur not just from other Castor transactions, but also from direct database access. Consider another application modifying the exact same record through direct JDBC access, or a remote server connecting to the same database. To detect such conflicts Castor uses a dirty checking mechanism.
When an object is about to be stored, Castor compares the current values in the database records with those known when the object was originally loaded from the database. Any changes are regarded as dirty fields and cause the transaction to rollback with the proper error message.
Not all fields are necessarily sensitive to dirty checking. The balance in a bank account is a sensitive field, but the date of the last transaction might not be. Since the date does not depend on the original value of the account, but on the last modification to it, dirty checking can be avoided.
A field marked with dirty="ignore" will not take part in dirty checking. Furthermore, modifications to such a field will not require a write lock on the object, further improving throughput. Marking fields as non-dirty should be done with extreme care.
The exclusive mode assures that no two transactions can use the same record at the same time. Exclusive mode works by acquiring a write lock in memory and synchronizing transactions through a lock mechanism with configured timeout.
Using in-memory locks, exclusive access provides some transaction synchronization that is efficient in terms of performance and increases the chance of a commit being successful. It does not, however, guarantee commit. Since the lock is acquired by Castor, it can be used to synchronize Castor access, but other forms of direct database access may still modify the database record.
When a transaction obtains an object that was specified as exclusive access in the mapping file or when performing a query, Castor will always obtain a write lock on that object. The write lock will prevent a second transaction from being able to access the object either for read or write, until the current transaction commits. If the object is already being accessed by another transaction, the current transaction will block until the other transaction commits and release the lock.
It is possible to upgrade from a shared to an exclusive lock by calling the
org.exolab.castor.jdo.Database.lock(java.lang.Object)
method. This method can be used with shared objects when the application
wants to assure that other transactions will be blocked and changes can be
made to the current object.
Because direct database access can modify the same record as represented by an exclusive locked object, Castor uses dirty checking when updating the database. Dirty checking does not have a severe affect on performance, and can be disabled by marking all the fields of the object with dirty="ignore".
To reduce the possibility of dirty reads, Castor will always synchronize
exclusive locked objects with the database at the beginning of a transaction.
That is, when an object is loaded the first time in a transaction with an
exclusive lock, Castor will retrieve a fresh copy of the object from the
database. Castor will not, however, refresh the object if the lock is upgraded
in the middle of a transaction using the lock method.
Exclusive mode does cause lock contention and can have an affect on application performance when multiple transactions attempt to access the same record. However, when used smartly with on a small set of objects it can help reduce the possibility of concurrency conflicts. It can also be used to force an object to be loaded from the database and the cache refreshed.
The locked mode performs optimistic locking using the underlying database engine to assure that only one transaction has access to the record. In addition to acquiring a write lock in memory, Castor performs a query with a special SQL construct (FOR UPDATE in Oracle, HOLDLOCK in Sybase) to guarantee access by one transaction.
In the event that the same database record will be accessed directly through JDBC, stored procedure, or a second machine using Castor, the only way to achieve object locking is through the database layer. However, such write locks should be cooperative, that is, other forms of database access should attempt to use the same locking mechanism.
In some isolation levels, when Castor acquires a write lock on the database it will prevent other applications from accessing the same record until the Castor transaction commits. However, certain isolation levels allow other applications to obtain a dirty image of the record.
Write locks on the database have a severe impact on application performance. They incur overhead in the database manager, and increase lock contention. It is recommended to use database locks with care, pay extra attention to the isolation level being used, and follow good practices recommended by the database vendor with regards to such locks.
In the future long transaction will be supported. Long transactions rely on the dirty checking mechanism and only hold connections open for as long as they are required for queries. Long transactions cannot be used with database locking.
Locked mode must be specified for the object in the mapping file or when conducting the query. It is not possible to upgrade to a locked lock in the middle of a transaction.
Objects loaded in this mode are always synchronized with the database, that is, they will never be obtained from the cache and always re-loaded for each new transaction.
When a query is performed in read-only mode or no mode is specified and the object is marked as read-only in the database, Castor will return a transient object. The returned object will not be locked and will not participate in the transaction commit/rollback.
When the same object is queried twice in a transaction as read-only, Castor will return two separate objects, allowing the caller to modify one object without altering the other. Castor will utilize the cache and only perform one load from the database to the cache.
Read-only access is recommended only when the object is intentionally queried as read-only and changes to the object should not be reflected in the database. If the object will not be modified, or modifications will be stored in the database, it is recommended to use the shared mode. Shared mode allows the same object to be returned twice in the same transaction.
The visibility of changes occuring in one transaction to other transactions depends upon the transaction isolation level specified for the database connection. Whether or not the changes are visible in the current transaction depends upon the operation being done.
There are four types of changes, the following table summarizes the affect of each change in one transaction on other queries in that transaction as well as other transactions.
Table 4.8. Changes
| Type of change | Same transaction | Other transaction |
|---|---|---|
| Create new object | New object is visible and will be returned from a query | New object might be visible, depending on isolation level, but access is blocked until the first transaction completes |
| Delete existing object | Object is no longer visible and will not be returned from a query | Object might not be visible, depending on isolation level, but access is blocked until the first transaction completes |
| setXXX() | Change is visible in object itself | Change is not visible, object is accessible depending on lock |
| update() | Change is visible in object itself | Change might be visible, depending on isolation level, object might be accessible depending on lock |
The Castor persistence engine is based on a layer architecture allowing different APIs to be plugged on top of the system, and different persistence engines to be combined in a single environment.
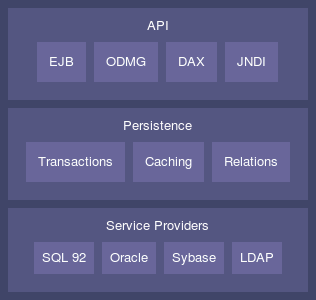
At the top level are the application level APIs. These are industry standard APIs that allow an application to be ported in and to other environments. These APIs consist of interfaces as well as semantics that make them suitable for a particular type of applications.
At the medium level is the Castor persistence mechanism. The persistence mechanism exposes itself to the application through the application level APIs. These typically have a one to one mapping with the persistence mechanism API. The persistence mechanism takes care of object caching and rollback, locking and deadlock detection, transactional integrity, and two phase commit.
At the bottom level are the Castor service providers. SPIs provide the persistence and query support into a variety of persistence mechanism. This version of Castor is bundled with an SQL 92 and LDAP persistence SPIs. Additional SPIs can be added, for example, alternative engines streamlined for Oracle, Sybase, DB2 and other databases.
This document will describe the persistence mechanism API and SPI to allow for those interested in adding new top level APIs or service providers.
The persistence mechanism is responsible for object caching and rollback, locking and deadlock detection, transaction integrity and two phase commit. All data access goes through the persistence mechanism. All operations are performed in the context of a transaction, even if the underlying SPI does not support transactions (e.g. LDAP).
The persistence API is defined in the package
org.exolab.castor.persist.
The persistence mechanism implements the
org.exolab.castor.persist.PersistenceEngine
interface, which allows objects to be loaded, created, deleted and locked
in the context of a transaction. The actual implementation is obtained from
org.exolab.castor.persist.PersistenceEngineFactory.
All operations are performed through the context of a transaction. A transaction is required in order to properly manage locking and caching, and to automatically commit or rollback objects at transaction termination (write-at-commit). Persistence operations are performed through the org.exolab.castor.persist.TransactionContext interface.
The actual implementation of a transaction context is specific to each
application API and set of SPIs. One is created from an
org.exolab.castor.persist.XAResourceSource
which abstracts the data source for the purpose of connection pooling and
XA transaction enlistment. A default implementation of
XAResource is available from
org.exolab.castor.persist.XAResourceImpl.
Every persistence operation is performed within the context of a transaction. This allows changes to objects to be saved when the transaction commits and to be rolled back when the transaction aborts. Using a transactional API relieves the application developer from worrying about the commit/rollback phase. In addition it allows distributed transactions to be managed by a transactional environment, such as an EJB server.
Each time an object is retrieved or created the operation is performed in the context of a transaction and the object is recorded with the transaction and locked. When the transaction completes, the modified object is persisted automatically. If not all objects can be persisted, the transaction rolls back. The transaction context implements full two phase commit.
Each transaction sees it's own view of the objects it retrieves from persistent storage. Until the transaction commit, these changes are viewable only within that transaction. If the transaction rolled back, the objects are automatically reverted to their state in persistent storage.
The transaction context
(org.exolab.castor.persist.TransactionContext)
is the only mechanism by which the top level APIs can interact with the
persistence engine. A new transaction must be opened in order to perform
any operation.
A transaction context is not created directly, but through a derived class that implements the proper mechanism for obtaining a new connection, committing and rolling back the connection. Note that commit and rollback operations are only required in a non-JTA environment. When running inside a JTA environment (e.g. an EJB server), the container is responsible to commit/rollback the underlying connection.
Application level APIs implement data sources that can be enlisted directly
with the transaction monitor through the JTA
XAResource
interface. A data source can be implemented using
org.exolab.castor.persist.XAResourceSource
which serves as a factory for new transaction contexts and
org.exolab.castor.persist.XAResourceImpl
which provides an XAResource implementation.
Each object participating in a transaction is associated with an object
identifier, or OID
(org.exolab.castor.persist.OID).
The OID identifies the object through its type and identity value.
The identity object must be unique across all OIDs for the same object type
in the same persistence engine.
Each object is also associated with a lock
(org.exolab.castor.persist.ObjectLock).
An object lock supports read and write
locks with deadlock detection. Any number of transactions may acquire a
read lock on the object. Read lock allows the transaction to retrieve the
object, but not to delete or store it. Prior to deleting or storing the
object, the transaction must acquire a write lock. Only one transaction
may acquire a write lock, and a write lock will not be granted if there
is any read lock on the object.
If an object is loaded read-only, a read lock is acquired at the begin of the load operation and realeased when the load is finished. Someone now could ask why do you acquire a read lock at all if it only lasts during the load operation. For an explanation we have to take a look on what happens if an object is loaded. Loading one object from database may cause castor to load a whole tree of objects with relations to each other. In the background castor may performs various queries to load all related objects. For this object tree to be consistent and reflect the persistent state of all the objects in the database at one point in time we need to lock all objects involved in all load operations to prevent any involved object to be write locked and changed by another transaction. If the load operation is finished these read locks are not required anymore. On the other hand, read locks are acquired to prevent an object already locked in the write mode from getting the read lock.
Write locks are acquired at the begin of the load operation similar then read locks. But in contrast to read locks, write locks are hold until the transaction is commited or rolled back. Holding the write lock until the end of the transaction is required as the changes to the objects, that could happen anytime between begin and end of the transaction, are only persisted if the transaction successfully commits.
If a transaction requires a read lock on an object which is write locked
by another transaction, or requires a write lock on an object which is read
or write locked by another transaction, the transaction will block until the
lock is released, or the lock timeout has elapsed. The lock timeout is a
property of the transaction and is specified in seconds. A
org.exolab.castor.persist.LockNotGrantedException
is thrown if the lock could not be acquired within the specified timeout.
This locking mechanism can lead to the possibility of a deadlock. The object lock mechanism provides automatic deadlock detection by tracking blocked transactions, without depending on a lock wait to timeout.
Write locks and exclusive locks are always delegated down to the persistence storage. In a distributed environment the database server itself provides the distributed locking mechanism. This approach assures proper concurrency control in a distributed environments where multiple application servers access the same database server.
The concurrency engine includes a layer that acts as a cache engine.
This layer is particularly useful for implementing optimistic locking and
reducing synchronization with the database layer. It is also used to perform
dirty checks and object rollback. The cache engine is implemented in
org.exolab.castor.persist.CacheEngine and
exposed to the application through the
org.exolab.castor.persist.PersistenceEngine.
When an object is retrieved from persistent storage it is placed in the cache engine. Subsequent requests to retrieve the same object will return the cached copy (with the exception of pessimistic locking, more below). When the transaction commits, the cached copy will be updated with the modified object. When the transaction rolls back, the object will be reverted to its previous state from the cache engine.
In the event of any error or doubt, the cached copy will be dumped from the cache engine. The least recently used objects will be cleared from the cache periodically.
The cache engine is associated with a single persistence mechanism, e.g. a database source, and LDAP directory. Proper configuration is the only way to assure that all access to persistent storage goes through the same cache engine.
The concurrency engine works in two locking modes, based on the type of access requested by the application (typically through the API). Pessimistic locking are used in read-write access mode, optimistic locking are used in exclusive access mode.
In optimistic locking mode it is assumed that concurrent access to the same object is rare, or that objects are seldom modified. Therefore objects are retrieved with a read lock and are cached in memory across transactions.
When an object is retrieved for read/write access, if a copy of the object exists in the cache, that copy will be used. A read lock will be acquired in the cache engine, preventing other Castor transactions from deleting or modifying the object. However, no lock is acquired in persistent storage, allowing other applications to delete or modify the object while the Castor transaction is in progress.
To prevent inconsistency, Castor will perform dirty checking prior to storing the object, detecting whether the object has been modified in persistent storage. If the object has been modified outside the transaction, the transaction will rollback. The application must be ready for that possibility, or resort to using pessimistic locking.
In pessimistic locking mode it is assumed
that concurrent access to the same object is the general case and that
objects are often modified. Therefore objects are retrieved with a write
lock and are always synchronized against the persistence storage. When
talking to a database server, a request to load an object in exclusive mode
will always load the object (unless already loaded in the same transaction)
using a SELECT .. FOR UPDATE which assures no other application
can change the object through direct access to the database server.
The locking mode is a property of the chosen access mode. The two access modes as well as read-only access can be combined in a single transaction, as a property of the query or object lookup. However, it is not possible to combine access modes for the same object, in certain cases this will lead to a conflict.
The pessimistic locking mode is not supported in LDAP and similar non-transactional servers. LDAP does not provide a mechanism to lock records and prevent concurrent access while they are being used in a transaction. Although all Castor access to the LDAP server is properly synchronized, it is possible that an external application will modify or delete a record while that record is being used in a Castor transaction.
Castor supports a service provider architecture that allows different persistence storage providers to be plugged in. The default implementation includes an SQL 92 provider and an and an LDAP provider. Additional providers will be available optimized for a particular database server or other storage mechanisms.
The service provider is defined through two interfaces, org.exolab.castor.persist.spi.Persistence and org.exolab.castor.persist.spi.PersistenceQuery. The first provides creation, deletion, update and lock services, the second is used to process queries and result sets. Service providers are obtained through the org.exolab.castor.persist.spi.PersistenceFactory interface.
The interface org.exolab.castor.persist.spi.Persistence defines the contract between the persistence mechanism and a persistence service provider. Each persistence storage (i.e. database server, directory server) is associated with a single persistence engine, which in turn contains a number of service providers, one per object type. Service providers are acquired through a org.exolab.castor.persist.spi.PersistenceFactory interface, which is asked by each persistence engine to return implementations for all the object types supported by that persistence engine.
The object's identity is an object that unique identifies the object within persistent storage. Typically this would be the primary key on a table, or an RDN for LDAP. The identity object may be a simple type (e.g. integer, string) or a complex type.
The service provider may support the stamp mechanism for efficiently tracking dirty objects. The stamp mechanism is a unique identifier of the persistent object that changes when the object is modified in persistent storage. For example, a RAWID in Oracle or TIMESTAMP in Sybase. If a stamp is return by certain operations it will be stored with the object's OID and passed along to the store method.
The create method is called to create a new object
in persistent storage. This method is called when the created object's
identity is known. If the object's identity is not know when the object is
made persistent, this method will be called only when the transaction
commits. This method must check for duplicate identity with an already
persistent object, create the object in persistent storage, such that
successful completion of the transaction will result in durable storage,
and retain a write lock on that object for the duration of the transaction.
The load method is called to load an object from
persistent storage. An object is passed with the requested identity. If the
object is found in persistent storage, it's values should be copied into the
object passed as argument. If the lock flag is set, this method must create
a write lock on the object at the same time it loads it.
The load method is called in two cases, when an
object is first loaded or when an object is synchronized with the database
(reloaded) in exclusive access mode. In the second case this method will
be called with an object that is already set with values that are not
considered valued, and must reset these values.
The store method is called to store an object into
persistent storage. The store method is called for an object that was loaded
and modified during a transaction when the transaction commits, as well as
for an object that was created during the transaction. This method must
update the object in persistent storage and retain a write lock on that
object.
This method might be given two views of an object, one that is being saved and one that was originally loaded. If the original view is provided as well, this method should attempt to perform dirty check prior to storing the object. Dirty check entails a comparison of the original object against the copy in persistent storage, to determine whether the object has changed in persistent storage since it was originally loaded. The class descriptor will indicate whether the object is interested in dirty checking and which of its fields should be checked.
The delete method is called to delete an object
from persistent storage. The delete method is called when the transaction
commits and expects the object to deleted, if it exists. This method is not
called when the transaction rolls back, objects created during the
transaction with the create method are automatically rolled back by the
persistent storage mechanism.
The writeLock method is called to obtain a write
lock on an object for which only a read lock was previously obtained.
The changeIdentity method is called to change
the identity of the object after it has been stored with the old identity.
The key generator gives a possibility to generate identity field
values automatically. During create the value of the
identity field is set to the value obtained from the key generator.
Different algorithms may be used here, both generic and specific
for database server.
The key generator for the given class is set in the mapping specification
file (mapping.xml), in the
key-generator attribute of the
class element, for example:
<class name="myapp.ProductGroup" identity="id" key-generator="MAX"> <field name="id"> </field> </class>
The following key generator names are supported in Castor 1.0:
Table 4.9. Supported key generator names
| MAX | "MAX( pk ) + 1" generic algorithm |
| HIGH-LOW | HIGH-LOW generic algorithm |
| UUID | UUID generic algorithm |
| IDENTITY | Supports autoincrement identity fields in Sybase ASE/ASA, MS SQL Server, MySQL and Hypersonic SQL |
| SEQUENCE | Supports SEQUENCEs in Oracle, PostgreSQL, Interbase and SAP DB |
Some of these algorithms have parameters, which can be specified
in the key-generator element of the mapping
specification file, for example:
<key-generator name="HIGH-LOW"> <param name="table" value="SEQ"/> <param name="key-column" value="SEQ_TableName"/> <param name="value-column" value="SEQ_MaxPKValue"/> <param name="grab-size" value="1000"/> </key-generator> <class name="myapp.ProductGroup" identity="id" key-generator="HIGH-LOW"> <field name="id"> </field> </class>
It is possible to create several key generators with the same
algorithms but different parameters.
In this case you have to specify the alias attribute
in the key-generator element, for example:
<key-generator name="SEQUENCE" alias="A"> <param name="sequence" value="a_seq"/> </key-generator> <key-generator name="SEQUENCE" alias="RETURNING"> <param name="sequence" value="b_seq"/> <param name="returning" value="true"/> </key-generator> <class name="myapp.ProductGroup" identity="id" key-generator="RETURNING"> <field name="id"> </field> </class>
Below all supported key generators a described in details.
MAX key generator fetches the maximum value of the primary key and lock the record having this value until the end of transaction. Then the generated value is set to (MAX + 1). Due to the lock concurrent transactions which perform insert to the same table using the same key generator algorithm will wait until the end of the transaction and then will fetch new MAX value. Thus, duplicate key exception is almost impossible (see below). Note, that it is still possible to perform multiple inserts during the same transaction.
There is one "singular" case of this algorithm: the case when the table is empty. In this case there is nothing to lock, so duplicate key exception is possible. The generated value in this case is 1.
This algorithm has no parameters. Primary key must have type integer, bigint or numeric.
This key generator uses one of the variants of the generic HIGH-LOW algorithm. It is needed a special auxiliary table ("sequence table") which has the unique column which contains table names (of the type char or varchar) and the column which is used to reserve values of the primary keys (of the type integer, bigint or numeric). The key generator seeks for the given table name, reads the last reserved value and increases it by some number N, which is called "grab size". Then the lock on the auxiliary table is released, so that concurrent transactions can perform insert to the same table. The key generator generates the first value from the grabbed interval. During the next (N - 1) invocations it generates the other grabbed values without database access, and then grabs the next portion. Note, that the auxiliary table must be in the same database as the table for which key is generated. So, if you work with multiple databases, you must have one auxiliary table in each database.
If the grab size is set to 1, the key generator each time stores the true maximum value of the primary key to the auxiliary table. In this case the HIGH-LOW key generator is basically equivalent to the MAX key generator. On you want to have LOW part of the key consisting of 3 decimal digits, set the grab size to 1000. If you want to have 2 LOW bytes in the key, set the grab size to 65536. When you increase the grab size, the speed of key generation also increases because the average number of SQL commands that are needed to generate one key is (2 / N). But that average number of key values that will be skipped (N / 2) also increases.
The HIGH-LOW key generator has the following parameters:
Table 4.10. parameters of the HIGH-LOW key generator
| table | The name of the special sequencetable. | Mandatory |
| key-column | The name of the column which contains table names | Mandatory |
| value-column | The name of the column which is used to reserve primary key values | Mandatory |
| grab-size | The number of new keys the key generator should grab from the sequence table at a time. | Optional, default="10" |
| same-connection | To use the same Connection for writing to the sequence table, values: "true"/"false". This is needed when working in EJB environment, though less efficient. | Optional, default="false" |
| global | To generate globally unique keys, values: "true"/"false". | Optional, default="false" |
| global-key | The name of key, which is used when globally unique keys are generated. | Optional, default="<GLOBAL>" |
If the parameter global is set to true,
the sequence table contains only one row with the value set in parameter
global-key (or "<GLOBAL>" if "global-key was not set")
instead of the table name. This row serves for all tables.
Don't forget to set same-connection="true" if you are working in EJB environment!
Note, that the class HighLowKeyGenerator is not final,
so you can extend it in order to implement other variants of HIGH-LOW
algorithm (for example, HIGH/MID/LOW or char key values).
This key generator generates global unique primary keys. The generated key is a combination of the IP address, the current time in milliseconds since 1970 and a static counter. The complete key consists of a 30 character fixed length string.
This algorithm has no parameters. Primary key must have type char, varchar or longvarchar.
IDENTITY key generator can be used only with autoincrement primary key columns (identities) with Sybase ASE/ASA, MS SQL Server, MySQL and Hypersonic SQL.
After the insert the key generator selects system variable
@@identity which contains the last identity value for
the current database connection.
In the case of MySQL and Hypersonic SQL the system functions
LAST_INSERT_ID() and IDENTITY()
are called, respectively.
This algorithm has no parameters.
The SEQUENCE key generator type is supported in conjunction with the following DBMS: Derby, Interbase, Oracle, PostgreSQL, and SAP DB.
It generates keys using database sequence objects.
The key generator has the following parameters:
Table 4.11. parameters of the SEQUENCE key generator
| sequence | The name of the sequence | Optional, default="{0}_seq" |
| returning | RETURNING mode for Oracle8i, values: "true"/"false" | Optional, default="false" |
| increment | Increment for Interbase | Optional, default="1" |
| trigger | Assume that there is a trigger that already generates key. Values: "true"/"false" | Optional, default="false" |
Usually one sequence is used for one table, so in general you have to define one key generator per table.
But if you use some naming pattern for sequences, you can use one key generator for all tables.
For example, if you always obtain sequence name by adding "_seq" to the name of the correspondent table, you can set "sequence" parameter of the key generator to "{0}_seq" (the default value).
In this case the key generator will use sequence "a_seq" for table "a", "b_seq" for table "b", etc. Castor also allows for inserting the primary key into the sequence name as well. This is accomplished by including the {1} tag into the "sequence" parameter. Example: "{0}_{1}_seq"
Actually the SEQUENCE key generator is "4 in 1". With PostgreSQL it performs "SELECT nextval(sequenceName)" before INSERT and produces identity value that is then used in INSERT. Similarly, with Interbase it performs "select gen_id(sequenceName, increment) from rdb$database" before INSERT.
With Oracle by default (returning=false) and with SAP DB it transforms the Castor-generated INSERT statement into the form "INSERT INTO tableName (pkName,...) VALUES (sequenceName.nextval,...)" and after INSERT it performs "SELECT seqName.currval FROM tableName" to obtain the identity value. With Oracle8i it is possible to use more efficient RETURNING mode: to the above INSERT statement is appened "RETURNING primKeyName INTO ?" and the identity value is fetched by Castor during INSERT, so that only one SQL query is needed.
In case when your table has an on_Insert trigger which already generates values for your key, like the following Oracle example:
create or replace trigger "trigger_name" before insert on "table_name" for each row begin select "seq_name".nextval into :new."pk_name" from dual; end;
you may set the "trigger" parameter to "true". This will prevent the "Sequence_name".nexval from being pulled twice (first time in the insert statement (see above), then in the trigger). Also usefull in combination with the "returning" parameter set to "true" for Oracle (in this case you may not specify the sequence name).
The usual Castor transactions are called here short transactions: an object is read, modified and written within the bounds of one transaction. Long transactions consist of two Castor transactions: an object is read in the first and written in the second. Between them the object is sent "outwards" and modified there. For example, the object may be send to a client application and dispayed to a user, or it may be sent to a servlet engine and is displayed on a web page. After that the modified object returns back and is written to the database in the second transaction. At this point the object is usually not the same physical instance as one that was read in the first transaction. The example code for writing the object in the second Castor transaction follows:
// a customer go to a webpage to review her personal information.
// The servlet then call this server side function: getCustomerInfo
public CustomerInfo getCustomerInfo( Integer customNum ) {
// in most case, users simply review information and
// make no change. Even if they make changes, it often
// takes time for them to decide. We don't want to
// lock the database row, so commit right after we load.
db.begin();
CustomerInfo info = (CustomerInfo)
db.load( CustomerInfo.class, customNum );
// we also want to keep track of customers patterns
// well...it helps us provide better service.
info.setLastVisit( today );
db.commit();
return info;
}
// Three days passed, the indecisive customer finally agrees to
// marry Joe. She changes her last name in the webpage and
// clicked the "Submit" button on the webpage.
// The servlet then calls updateCustomerInfo to update the
// last name for the indecisive customer.
public void updateCustomerInfo( CustomerInfo info ) {
db.begin();
db.update(info);
db.commit();
}
Note, that it is natural to read the object in the first transaction in the read-only mode.
Since the time interval between the first and the second
transaction is relatively big, it is desirable to perform dirty
checking, i.e. to check that the object has not been modified
in the database during the long transaction.
For that the object must hold a timestamp: it is set by
Castor during the first Castor transaction and is checked during
the second one.
In order to enable the dirty checking for long transactions,
the object should implement the interface
org.exolab.castor.jdo.TimeStampable
having two methods: long jdoGetTimeStamp() and
void jdoSetTimeStamp(long timeStamp)
The advantage of the bounded dirty checking is that it doesn't require any changes to the database schema. It uses the Castor cache to store object timestamps. The disadvantage of this algorithm is that it is bounded by a lifetime of the cached copy of the object. After the cached copy has been purged, db.update() causes ObjectModifiedException.
Thus, parameters of the cache define dirty checking capabilities. The cache-type attribute is part of the <class> element in the XML mapping. Consider the existing cache types:
none - the bounded dirty checking is impossible
count-limited - the count limit for the cache is a count limit for the objects of this class that can participate in long and short transactions simultaneously.
time-limited - the time limit for the cache is a time limit for the long transaction.
unlimited - the bounded dirty checking gives correct results while the cache exists, i.e. until the crash of the server.
For long transactions (detached objects) it was required that the entity has been kept in cache from being loaded until its update. If the entity was expired from cache before the update an ObjectModifiedException had been thrown. While this is no problem if all entities of an application can be kept in cache all the time, it is one for large scale applications with millions of entities.
With release 1.3 we have changed the handling of timestamps. While it is still possible to rely on cache only it is now also possible to persist the timestamp together with the other properties of the entity. Doing so will ensure that the timestamp do not change even if the entity got expired from cache from being loaded until it gets updated. If this happens the entity gets reloaded during update which also loads the previous timestamp. Having said that it still is possible that an ObjectModifiedException is thrown when another user has changed the same entity in the meantime.
See an example entity and its mapping below:
public class Entity implements TimeStampable { private Integer _id; private String _name; private long _timeStamp; public Integer getId() { return _id; } public void setId(final Integer id) { _id = id; } public String getName() { return _name; } public void setName(final String name) { _name = name; } public long getTimeStamp() { return _timeStamp; } public void setTimeStamp(final long timeStamp) { _timeStamp = timeStamp; } public long jdoGetTimeStamp() { return _timeStamp; } public void jdoSetTimeStamp(final long timestamp) { _timeStamp = timestamp; } }
<class name="Entity"> <cache-type type="time-limited" capacity="300"/> <map-to table="entity"/> <field name="id" type="integer" identity="true"> <sql name="id" type="integer"/> </field> <field name="name" type="string"> <sql name="name" type="char"/> </field> <field name="timeStamp" type="long"> <sql name="timestamp" type="numeric" /> </field> </class>
In some cases it is desirable to map a plain sequence of fields in a database record to more complicated structure of attributes in a Java object, where the target attributes are contained (nested) in other attributes. In brief, you can specify a path to the target attribute as a name of the field in a configuration file, and Castor is able to handle such nested attributes. For example:
<field name="address.country.code"...> <sql name="person_country"/> </field>
The first case is an attribute of an application type that is a container for some value of a Java type supported by Castor. Usually the application type also has some business methods. Examples are: class Balance that contains a BigDecimal value and has some accounting-specific methods; class CountryCode that contains a String value and has methods validate(), getDisplayName(), etc.; class Signature that contains a byte[] value and has some security-specific methods. In order to use such type with Castor you should provide a pair of methods to get/set the value of the Castor-supported type, e.g. getBigDecimal/setBigDecimal, getCode/setCode, getBytes/setBytes.
Assume that you have the class Address
public class Address { private CountryCode _country; private String _city; private String _street; public CountryCode getCountry() { return _country; } public void setCountry(CountryCode country) { _country = country; } ... }
where the class CountryCode is like this
public class CountryCode { private String _code; private static String[] _allCodes; private static String[] _allDisplayNames; public String getCode() { return _code; } public void setCode(String code) { _code = code; } public void getDisplayName() { ... }
then write in the configuration file:
<class name="Address"...> <field name="country.code"...> <sql name="addr_country"/> </field> ... </class>
When reading the object from the database Castor will use
object.getCountry().setCode(value);
to set the nested attribute value. Moreover, if object.getCountry() is null, Castor will create the intermediate object of the application type:
country = new CountryCode();
country.setCode(value);
object.setCountry(country);
When writing the object to the database Castor will use
value = object.getCountry().getCode();
to get the value of the correspondent database field.
The second case is an attribute that is a part of a compound
attribute, which contains several database fields.
For example, database fields person_country, person_city,
person_street of the table PERSON
correspond to one compound attribute "address" of the class
Person:
public class Person { private String _firstName; private String _lastName; private Address _address; public Address getAddress() { return _address; } public void setAddress(Address address) { _address = address; } ... }
where the class Address is the same as in the
previous section. Then write in the configuration file:
<class name="Person"...> <field name="address.country.code"...> <sql name="person_country"/> </field> <field name="address.city"...> <sql name="person_city"/> </field> <field name="address.street"...> <sql name="person_street"/> </field> ... </class>
Similarly to the previous section, Castor will use a proper sequence of get/set methods to access the nested attributes and will create the intermediate objects when necessary. Don't forget to provide parameterless constructors for the container classes.
10/22/2004: Added JDBC Datasource configuration for mySQL.
9/14/2004: Added section about using Jakarta's DBCP with Castor.
There is no mechanism within Castor JDO to provide pooling of JDBC drivers. Rather, Castor JDO relies on the drivers or external driver wrappers to implement a pooling mechanism. Some drivers, such as Oracle, provides a pooling mechanism in the driver. For those that do not, there are tools such as Proxool and Jakarta's DBCP project.
Here, I'll go over the various usage of the PostgreSQL driver
with Castor. We start with the most basic configurations
that do not use any pooling, to those with pooling via DBCP.
I'll include how to configure the pooling version of the
PostgreSQL JDBC driver ths will be usable with PostgreSQL 7.3 and
later, how to setup a Tomcat JNDI context that Castor can use to get
a pooled JDBC connection. Finally, I'll explain how to configure a
BasicDataSource from the DBCP package using the
<data-source> element.
A standard jdo-conf.xml entry for using PostgreSQL without pooling looks like this:
<driver class-name="org.postgresql.Driver" url="jdbc:postgresql://localhost/app"> <param name="user" value="smith"/> <param name="password" value="secret" /> </driver>
On the other hand, if you wanted to use the PostgresqlDataSource, you would use the data-source tag instead, and the connection entry would look like this:
<data-source class-name="org.postgresql.PostgresqlDataSource"> <param name="server-name" value="localhost" /> <param name="database-name" value="app" /> <param name="user" value="smith" /> <param name="password" value="secret" /> </data-source>
(Note that only versions before 7.3 of the PostgreSQL JDBC driver include this class)
In the 7.3 release of PostgreSQL, they will start providing a pooling mechanism with their driver. The Castor SVN repository includes a beta version of the driver with this functionality. Here is the 'current' configuration needed for the upcoming 7.3 release of PostgreSQL. (Unless they change it.) Note that in this pooling mechanism currently lacks some features of standrd pooling packages such as DBCP, such as timing out idle connections and removing failed connections from the pool. In this case, we can create the following data-source entry in the jdo-conf.xml file to provide for our connections with Castor.
<data-source class-name="org.postgresql.jdbc2.optional.PoolingDataSource"> <param name="server-name" value="localhost" /> <param name="database-name" value="app" /> <param name="initial-connections" value="2" /> <param name="max-connections" value="10" /> <param name="user" value="smith" /> <param name="password" value="secret" /> </data-source>
Here is the configuration needed for using a connection pool with the Oracle JDBC DataSource implementations.
<data-source class-name="oracle.jdbc.pool.OracleConnectionCacheImpl"> <param name="URL" value="jdbc:oracle:thin:@localhost:1521:TEST" /> <param name="user" value="scott" /> <param name="password" value="tiger" /> </data-source>
Here is the configuration needed for using a connection pool with the mySQL JDBC DataSource implementations.
<data-source class-name="com.mysql.jdbc.jdbc2.optional.MysqlConnectionPoolDataSource"> <param name="server-name" value="localhost" /> <param name="port" value="3306" /> <param name="user" value="scott" /> <param name="password" value="tiger" /> <param name="database-name" value="test" /> </data-source>
Finally, I want to show the configuration for using a pooling data-source for Castor which is retrieved from a JNDI context that Apache fills. The first example is using the PostgreSQL pooling data-source, and the second is using Castor. The information to gain here is that we did not need to change the jdo-conf.xml file or the webapp's web.xml file to achieve this.
First, we modify the deployment context for the webapp in Tomcat >= 4.0 for our
webapp in the conf/server.xml directory. (With Tomcat/Catalina releases 4.0 and higher
there's more than one way of adding a
<Resource> entry. Please consult with the
manuals for more and more detailed information).
We add the following information (using the PostgreSQL JDBC DataSource implementations as introduced above.):
<Context path="/webapp" docBase="test" debug="10"> <Resource name="jdbc/appDb" auth="Container" type="org.postgresql.jdbc2.optional.PoolingDataSource"/> <ResourceParams name="jdbc/appDb"> <parameter> <name>factory</name> <value>org.postgresql.jdbc2.optional.PGObjectFactory</value> </parameter> <parameter> <name>dataSourceName</name> <value>appDb</value> </parameter> <parameter> <name>initialConnections</name> <value>2</value> </parameter> <parameter> <name>maxConnections</name> <value>5</value> </parameter> <parameter> <name>databaseName</name> <value>app</value> </parameter> <parameter> <name>user</name> <value>smith</value> </parameter> <parameter> <name>password</name> <value>secret</value> </parameter> <parameter> <name>serverName</name> <value>localhost</value> </parameter> </ResourceParams> </Context>
Here, we are using the PostgreSQL PGObjectFactory which provides the JNDI server (Tomcat) the ability to create the correct data source. Now, the web.xml file for the webapp needs to be updated too.
<resource-env-ref> <description>PostgreSQL pooling check</description> <resource-env-ref-name>jdbc/appDb</resource-env-ref-name> <resource-env-ref-type>javax.sql.DataSource</resource-env-ref-type> </resource-env-ref>
Note that we are only calling the ref type a DataSource object, not using the PostgreSQL class name. This will enable us to make changes easily. Now, in the jdo-conf.xml file that Castor uses, we no longer list the driver or data-source tag, but use the JNDI one, and it is simply this:
<jndi name="java:comp/env/jdbc/appDb"/>
Commons-DBCP provides database connection pooling services, and together with Commons-Pool it is the default JNDI datasource provider for Tomcat.
With release 1.1 of the Jakarta Commons DBCP component, one of the major new features of the JDBC 3.0 API has (finally) been added to BasicDataSource, support for prepared statement pooling.
To configure Castor for the use of DBCP, please provide the following <data-source> entry in the jdo-conf.xml file.
<data-source class-name="org.apache.commons.dbcp.BasicDataSource">
<param name="driver-class-name" value="com.mysql.jdbc.Driver" />
<param name="username" value="test" />
<param name="password" value="test" />
<param name="url" value="jdbc:mysql://localhost/test" />
<param name="max-active" value="10" />
</data-source>
As mentioened above, please note that with DBCP 1.1 and later releases, support for prepared statement pooling has been added to DBCP. As Castor JDO does not implement prepared statement pooling itself, you will to configure DBCP explicitely to enable this feature.
To configure Castor for the use of DBCP, and to turn prepared statement
pooling on, please provide the following
<data-source> entry in the
jdo-conf.xml file.
<data-source class-name="org.apache.commons.dbcp.BasicDataSource">
<param name="driver-class-name" value="com.mysql.jdbc.Driver" />
<param name="username" value="test" />
<param name="password" value="test" />
<param name="url" value="jdbc:mysql://localhost/test" />
<param name="max-active" value="10" />
<param name="pool-prepared-statements" value="true" />
</data-source>
There's plenty of information on configuration of BasicDataSource.
PostgreSQL's blob support has evolved over the years. Today PostgreSQL fields can be of unlimited length. And there are specific data types for character and binary large objects. The current Castor support for blobs, however, uses an earlier PostgreSQL blob support. This support places the blob data in the pg_largeobject table and a object id in the referring table. For most practical purposes using this earlier support does not matter.
Database version and the JDBC driver version matter greatly. To get everything to work I eventually built and installed PostgreSQL 7.2.2 and used the JDBC driver from this build (i.e. not the one from http://jdbc.postgresql.org.
Since Castor is using the earlier blob support the JDBC has to be placed in PostgreSQL 7.1 comparability mode. To do this use the following JDBC URL
jdbc:postgresql://host:port/database?compatible=7.1
Once you have resolved the PostgreSQL version issues Castor works as documented.
Here are the details of an example configuration.
Client Windows 2000, Sun Java Standard Edition 1.3.1_03, Castor 0.9.3.21 Server RedHat 7.2, PostgreSQL 7.2.2
The interface I am using is
public interface Document { String getTitle(); void setTitle( String title ); Date getCreatedOn(); void setCreatedOn( Date createdOn ); String getContentType(); void setContentType( String contentType ); InputStream getContent(); void setContent( InputStream content ); }
and this is implemented by the class DocumentImpl.
The mapping file is
<?xml version="1.0"?> <mapping> <class name="com.ingenta.DocumentImpl" identity="id" key-generator="SEQUENCE" > <description /> <cache-type type="none" /> <map-to table="documents" /> <field name="id" type="integer" > <sql name="id" type="integer" dirty="check" required="true"/> </field> <field name="title" type="string"> <sql name="title" type="longvarchar" dirty="check" /> </field> <field name="createdOn" type="date"> <sql name="createdon" type="date" dirty="check" /> </field> <field name="contentType" type="string"> <sql name="contenttype" type="longvarchar" dirty="check" /> </field> <field name="content" type="stream"> <sql name="content" type="blob" dirty="ignore" /> </field> </class> </mapping>
Note that the blob is not dirty checked.
And the SQL is
create table documents (
id serial not null,
title text null,
createdon timestamp null,
contenttype text null,
content oid null,
primary key ( id )
);
Castor caches objects between transactions for performance. With a blob however the cached object's InputStream is not reusable. To workaround this I have told the cache to not cache any objects of this class by adding to the class mapping, as noted above.
There's many users of Castor JDO out there, who (want to) use Castor JDO in in high-volume applications. To fine-tune Castor for such environment, it is necessary to understand many of the product features in detail and to be able to balance their use according to the application needs. Even though many of these features are detailed in various places, people have frequently been asking for a 'best practise' document, a document that brings together these technical topics (in one place) and presents them as a set of easy-to-use recipes.
Please be aware that this document is under construction, but still we believe that - even when in its conception phase - it provides valuable information to users of Castor JDO.
Let's start with some general suggestions that you should have a look at. Please don't feel upset if some are really primitive but there may be users reading this document that are not aware of them.
Switch to version 0.9.9 of Castor as we have fixed some 100+ bugs that may causesome of your problems.
Sidenote: Performance has, generally, improved recently. If you're not seeing performance improvements, then it's worth spending some time thinking about why.
Initialize your JDOManager instance once and reuse it all over your application. Don't reuse the Database instances. Creating them is inexpensive, and JDBC rules state that one thread <-> one JDBC connection is the rule. Do not multithread inside of a Database instance; as a corrolary, do not multithread on a single JDBC connection.
Use a Datasource instead of a Driver configuration as they enable connection pooling which gives you a great performance improvement.
We highly suggest DBCP, here, with the beneficial use of prepared statement caching.
Should you be running on a system where read performance is
critical, feel free to take the SQL code generated by castor,
and dumped to logs during the DB mapping load in debug output,
and turn those into stored procedures that you then invoke via
SQL CALL to perform those loads; however, I find personally that
stored procedures would be a minimal improvement over the DBCP
prepared statement cache; your mileage may vary.
db.load() has performance benefits that
are worth keeping, IMO, and the pleasure of having pretty stored
procedures in your database is far outweighed by the nightmare
of change management.
Have a look at the HTML docs for Jakarta DBCP, which has details about how to use and configure DBCP with Castor and Tomcat.
| Note |
|---|---|
'prepared statement caches' refer to the fact that DBCP is a JDBC 3.0-compliant product, and as such has to support caching of prepared statements. This basically allows the JDBC driver to maintain a pool of prepared statements across all connections, a feature that has been added to the JDBC specification with release 3.0 only. |
DBCP setup is generally outside of the scope of this list, but basically, here's my two cent description:
Use tomcat 5.5, because mucking about in server.xml sucks. For those of you working with Tomcat 4.1.x, there's no need to muck about in server.xml, either. Afaik, a web app can be deployed using a web app descriptor copied into $TOMCAT_HOME/webapps, which is the place top define anything specific to a web app context. Details can vary, of course.
Create a META-INF directory in your WAR deploy scripts, and put a context.xml in it.
In that context.xml, describe all of the things you want to be made available via JNDI to your application. These include things like UserTransaction and TransactionManager (for those of us using JOTM), all your database connection pools as datasources, etc. You can also add your JDO factory here, should you choose to do so.
Configure Castor to load those JNDI names to retrieve connections.
Hit the deploy button, and bob's your uncle.
Always commit or rollback your transactions and close your Database instances properly; also in fail situations.
| Note |
|---|---|
Just the obvious general rule on Java objects that hold resources: Don't wait for the VM to finalize to have something happen to your objects when you could have released critical resources at the appropriate point in the codebase. |
Keep your transactions as short as possible. If you have an open transaction that holds a write lock on an object no other transaction can get a write lock on the same object which will lead to a LockNotGrantedException.
execute() {
Database db = jdo.getDatabase();
db.begin();
// query objects from database with read only
db.commit();
db.close();
// do some time consuming processing with the data
Database db = jdo.getDatabase();
db.begin();
// use db.load() to load the objects you need to change again
// create, update or delete some objects
db.commit();
db.close();
} It doesn't make sense to make a own transaction for every change you want to do to an object as this will slow down your application. On the other hand if you have transactions with lots of objects involved taking an valuable amonth of time you may consider to split this transactions to reduce the time an object is locked.
Also keep in mind that folks using lockmode of DBLocked do
FOR UPDATE calls on things they read while
the transaction is open; if you're using dblocked mode, be aware
of how your application does things. If you're in one of the
other modes, locks happen inside castor, and it's your
responsibility to always use the right access mode when accessing
content.
If you can, for example, decide at the API layer whether or not an operation is going to ever need to modify an object, and know that you will only ever use an instance in read only mode, load objects with access mode read only, and not shared.
Limit use of read-write objects to situations in which it is likely you will need to perform updates.
Imagine, for a moment, that these transactions were in DBLocked mode - transactions which translate directly into locks on the database.
If you're opening something up for modification on the DB
- marking it as select FOR UPDATE
- then that row will be locked until you commit.
The database would prevent any other transaction that wants to
touch that row from doing anything to it, and it would block on
your transaction - deadlock at the SQL level.
Castor does the same things internally for its own access modes - Shared and Exclusive. Each has different locking semantics; having good performance means understanding those locking semantics.
For example - read only transactions (should be) cheap. So there's no issue with holding those transactions open a long time; because they only translate, for an instant, into a lock. The lock is released the moment the load is completed and the object is dropped into read-only state within your transaction; read only operations therefore operate, pretty much, without locking.
The lock is of course acquired because you might also have it in SHARED or EXCLUSIVE mode on another thread - and that read-only operation isn't safe until those transactions close.
Once the lock is released, you're lock-free again, so the transaction basically has nothing in it that needs anything doing.
That's not to say that holding transactions open is good practice - but transactions should always be thought of as cheap to create and destroy and expensive to hold on to - never do heavy computation inside of one, unless you're willing to live with the consequences that arise from holding transactions on object sets that others might need to access.
Query or load your objects read only whenever possible. Even if castor creates a lock on them this does not prevent other threads from reading or writing them. Read only queries are also about 7 times faster compared with default shared mode.
for queries:
String oql = "select o from FooBar o"; Query query = db.getOQLQuery(oql); QueryResults results = query.execute(Database.ReadOnly);
to load an object by its identity:
Integer id = new Integer(7); Foo foo = (Foo) db.load(Foo.class, id, Database.ReadOnly);
Default accessmode is evaluated as follows:
if specified castor uses access mode from db.load() or query.execute(),
if this is not available it takes access mode specified in class mapping,
if nothing is specified in mapping it defaults to shared.
One cannot stress how important this is: If 99% of your application never writes an object, and you as a programmer know it won't, then do something about it. If you're in a situation where you want the object to be read-only most of the time, and only want a writable every now and then, do so just-in-time by performing a load-modify-store operation in a single transaction for the shareable you want.
In other words: Don't use read-write objects unless you know you're likely to want to write them.
If there is a possibility you should prefer
Database.load(Class, object) over
Query.execute(String). I suggest that as
load() first tries to load the requested
object from cache and only retrieves it from database when it is
not available there. When executing queries with
Query.execute() the object will always
be loaded from database without looking at the cache. You may gain
a improvement by a factor of 10 and more when changing from
Query.execute() to
Database.load().
We hope above suggestions help you to resolve the problems you have. If you still need more performance there are areas of improvement that are more difficult to resolve. For further ideas to improve your applications performance you should take a loock at out performance test suite (PTF) which you can find in Castor's source distribution under: src/tests/ptf/jdo.
Now, there's lots left to do - there is still the issue, for example, of dependent objects being slightly sub-optimal in performance both in terms of the SQL that gets generated and the way it gets managed - but there will be improvements over time to the way that this and other operations are performed.
But performance should be good right now. If it isn't, you'll need to think about whether you are using the optimal set of operations. No environment can predict your requirements - hinting to the system when objects can be safely assumed to be read-only is vital to a high-performance implementation.